public void check(){ if(date == null) thrownewIllegalArgumentException("date is missing"); LocalDate parsedDate; try{ parsedDate = LocalDate.parse(date); } catch(Exception e){ thrownewIllegalArgumentException("Invalid format for date", e); } if(parsedDate.isBefore(LocalDate.now())) thrownewIllegalArgumentException("date cannot be before today"); if(numberOfSeats == null) thrownewIllegalArgumentException("number of seats cannot be null"); if(numberOfSeats < 1) thrownewIllegalArgumentException("number of seats must be positive"); }
一个《Pragmatic Programmers》提供的比较有用的经验是: 我们相信异常在程序的正常流程里应该是很少使用的。异常应该表征不可预测的行为。假设一个没被抓住的异常是你的程序崩溃了,那么问问你自己,“如果我去掉了所有的异常处理器,程序还能否运行”,如果答案是NO,那么也许是在不应该使用Exception的地方使用了Exception。 – David Thomas and Andy Hunt
public void check(){ if(date == null) thrownewIllegalArgumentException("date is missing"); LocalDate parsedDate; try{ parsedDate = LocalDate.parse(date); } catch(Exception e){ thrownewIllegalArgumentException("Invalid format for date", e); } if(parsedDate.isBefore(LocalDate.now())) thrownewIllegalArgumentException("date cannot be before today"); if(numberOfSeats == null) thrownewIllegalArgumentException("number of seats cannot be null"); if(numberOfSeats < 1) thrownewIllegalArgumentException("number of seats must be positive"); }
public void validation() { if (date == null) thrownewIllegalArgumentException("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { thrownewIllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) thrownewIllegalArgumentException("date cannot be before today"); if (numberOfSeats == null) thrownewIllegalArgumentException("number of seats cannot be null"); if (numberOfSeats < 1) thrownewIllegalArgumentException("number of seats must be positive"); }
接下来,我会把validation的返回值改为返回一个notification。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classBookingRequest… publicNotificationvalidation() { *** Notification note = newNotification(); if (date == null) thrownewIllegalArgumentException("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { thrownewIllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) thrownewIllegalArgumentException("date cannot be before today"); if (numberOfSeats == null) thrownewIllegalArgumentException("number of seats cannot be null"); if (numberOfSeats < 1) thrownewIllegalArgumentException("number of seats must be positive"); *** return note; }
我现在可以检查notification,如果有错误的话,可以抛出一个异常了。
1 2 3 4 5
classBookingRequest… publicvoidcheck() { *** if (validation().hasErrors()) *** throw new IllegalArgumentException(validation().errorMessage()); }
class BookingRequest… public Notification validation() { Notification note = new Notification(); *** if (date == null) note.addError("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { throw new IllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) throw new IllegalArgumentException("date cannot be before today"); if (numberOfSeats == null) throw new IllegalArgumentException("number of seats cannot be null"); if (numberOfSeats < 1) throw new IllegalArgumentException("number of seats must be positive"); return note; }
class BookingRequest… public Notification validation() { Notification note = new Notification(); if (date == null) throw new IllegalArgumentException("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { throw new IllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) throw new IllegalArgumentException("date cannot be before today"); if (numberOfSeats == null) throw new IllegalArgumentException("number of seats cannot be null"); *** if (numberOfSeats < 1) note.addError("number of seats must be positive"); return note; }
前面的检查,是一个null的检查,所以我们需要使用条件判断来避免NPE。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
class BookingRequest… public Notification validation() { Notification note = new Notification(); if (date == null) throw new IllegalArgumentException("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { throw new IllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) throw new IllegalArgumentException("date cannot be before today"); *** if (numberOfSeats == null) note.addError("number of seats cannot be null"); *** elseif (numberOfSeats < 1) note.addError("number of seats must be positive"); return note; }
class BookingRequest… public Notification validation() { Notification note = newNotification(); if (date == null) throw newIllegalArgumentException("date is missing"); LocalDate parsedDate; try { parsedDate = LocalDate.parse(date); } catch (DateTimeParseException e) { throw newIllegalArgumentException("Invalid format for date", e); } if (parsedDate.isBefore(LocalDate.now())) throw newIllegalArgumentException("date cannot be before today"); *** validateNumberOfSeats(note); return note; }
private void validateNumberOfSeats(Notification note) { if (numberOfSeats == null) note.addError("number of seats cannot be null"); elseif (numberOfSeats < 1) note.addError("number of seats must be positive"); }
classBookingRequest… privatevoidvalidateNumberOfSeats(Notificationnote) { if (numberOfSeats == null) { note.addError("number of seats cannot be null"); return; } if (numberOfSeats < 1) note.addError("number of seats must be positive"); }
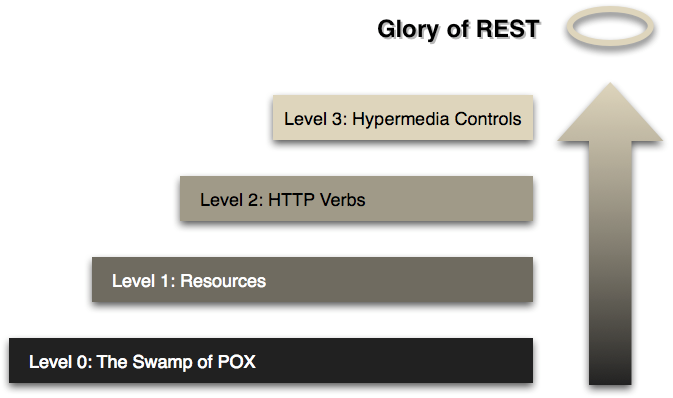
Leonard Richardson的模型将REST的基本元素分解到三个步骤当中。这三个步骤包括:资源(resources),http谓词(get, post, put, delete, head, option),超链接控制。
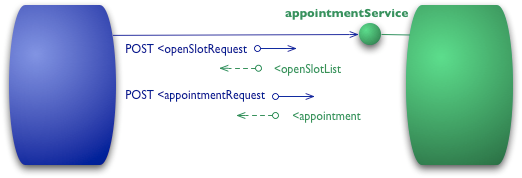
注:文章译自Martin Fowler博客,原文链接. 最近我(Martin Fowler)阅读了一本《Rest In Praces》,我的同事们写的一本书。他们的目的是解释如何使用Rest Web Service来解决企业级应用于道的集成难题。这本书的核心来自于一个观察,即当前的互联网(Web)就是一个大规模的分布式系统,并且它运行良好,所以我们可以借鉴互联网(Web)的组织方式来构建我们的集成系统。
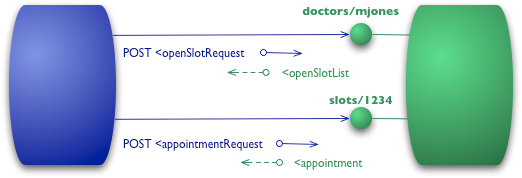
为了更好的解释类互联网(web-style)系统的详细属性,(Rest In Practise)作者们使用了restfult成熟度模型(注:这一模型由Leonard Richardson发现,并在QCon上提出)。该模型采用了很好的方式来思考如何使用Web相关的技术。所以我(Martin Fowler)会以自己的方式来解释一下Rest成熟度模型(下面的例子只是用作说明,不值得拿去编码测试)。
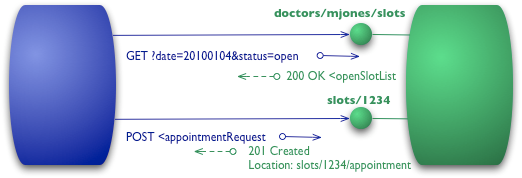
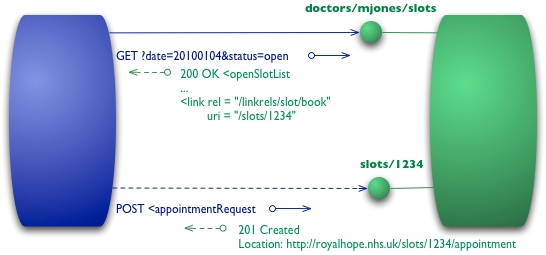
# Level 3-Hypermedia Controls 最后一个层次引入了大家耳熟能详的拥有丑陋缩写的HATEOAS(Hypertext As The Engine Of Application State)。它将问题从如何获取“空闲时段列表”转换成了要做什么才能预定到一个时段(抽象啊)。 我们从最开始的GET请求入手,和在Level 2中发送的请求一样。
到目前为止们还没有完整的标准来指导大家应该如何表征超链接控制。我当前所做的则是按照《REST in Practise》中推荐的那样(而他是遵从ATOM,RFC 4287的)。我使用元素,其中包含uri属性(其标示了目标URI)以及rel属性(其标示出了关系的类型)。一个通用的关系(例如self用来指向资源本身)是十分明显的,任何其他特定于该服务端的link都是一个合格的URI。ATOM表明熟知的linkrels是Registry Of Link Relations。我写的这些受到ATOM限制的,ATOM本身是在第三层restfulness的领导者。