@Test public void shouldPerformAddition() { Calculator calculator = newCalculator(new RoundingStrategy(), "unused", ENABLE_COSIN_FEATURE, 0.01, calculusEngine, false); int result = calculator.doComputation(makeTestComputation()); assertEquals(5, result); // Where did this number come from? }
public void deletePostsWithTag(Tag tag) { for (Post post : blogService.getAllPosts()) { if (post.getTags().contains(tag)) { blogService.deletePost(post.getId()); } } }
publicclassFakeBlogServiceimplementsBlogService{ privatefinal Set<Post> posts = new HashSet<Post>(); // Store posts in memory publicvoidaddPost(Post post){ posts.add(post); } publicvoiddeletePost(int id){ for (Post post : posts) { if (post.getId() == id) { posts.remove(post); return; } } thrownew PostNotFoundException("No post with ID " + id); } public Set<Post> getAllPosts(){ return posts; } }
Uri uri = cloudUploader.uploadFile(new File(“/path/to/foo.txt”)); // The uploaded file URI contains the user ID, file type, and upload ID. (Or does it?) assertThat(uri).isEqualTo(new Uri(“/testuser/text/uploadId.txt”));
@Test public void uploadFileToCloudStorage() { CloudUploader cloudUploader = newCloudUploader(cloudService); Uri uri = cloudUploader.uploadFile(”/path/to/foo.txt”); assertThat(cloudService.retrieveFile(uri)).isEqualTo(readContent(“/path/to/foo.txt)); }
@Mock MySalaryProcessor mockMySalaryProcessor; // Wraps the SalaryProcessor library ... // Mock the wrapper class rather than the library itself when(mockMySalaryProcessor.sendSalary()).thenReturn(PaymentStatus.SUCCESS);
Function WORD possible values: integers initialvalues: undefined parameters: l, w, c all integers effect: call ERLWEL if l < 1or l > p1 call ERLWNL if l > LINES call ERLWEW if w < 1or w > p2 call ERLWNE if w > WORDS(l) call ERLWEC if c < 1or c > p3 call ERLWNC if c > CHARS(l, w)
Function SETWRD possible values: non initialvalues: not applicable parameters: l,w,c,d all integers effect: call ERLSLE if l < 1or l > p1 call ERLSBL if l > 'LINES' + 1 call ERLSBL if l < 'LINES' call ERLSWE if w < 1or w > p2 call ERLSBW if w > 'WORDS'(l) + 1 call ERLSBW if w < 'WORDS'(l) call ERLSCE if c < 1or c > p3 call ERLSBC if c .noteq. 'CHARS'(l,w)+1 if l = 'LINES' + 1thenLINES = LINES + 1 if w = 'WORDS'(l) + 1then WORDS(l) = w CHARS(l, w) = c WORD(l,w,c) = d
Function WORDS possible values: integers initialvalues: 0 parameters: l an integer effect: call ERLWSL if l < 1or l > p1 call ERLWSL if l > LINES call ERLWSL(MN) if l > LINES
FunctionLINES possible values: integers initialvalue: 0 parameters: none effect: non Function DELWRD possible values: none initialvalue: not applicable parameters: l,w both integers effect: call ERLDLE if l < 1or l > LINES call ERLDWE if w < 1or w > 'WORDS'(1) call ERLDLD if'WORDS'(l) = 1 WORDS(l) = 'WORDS'(l) - 1 forall c WORD(l,v,c) = 'WORD'(l, v+1, c) if v >= w forall v > w or v = w CHARS(l, v) = 'CHARS'(l, v+1)
Function DELLINE possible values: none initialvalues: not applicable parameters: l an integer effect: call ERLDLL if l < 0or l > 'LINES' LINES = 'LINES' - 1 if r = 1or r > 1thenforall w, forall c (WORDS(r) = 'WORDS'(r+1) CHARS(r, w) = 'CHARS'(r+1, w) WORD(r, w ,c) = 'WORD'(r+1, w ,c))
Function CHARS possible vlaues: integer initialvalue: 0 parameters: l,w both integers effect: call ERLCNL if l < 1or l > LINES call ERLCNW if w < 1or w > WORDS(l)
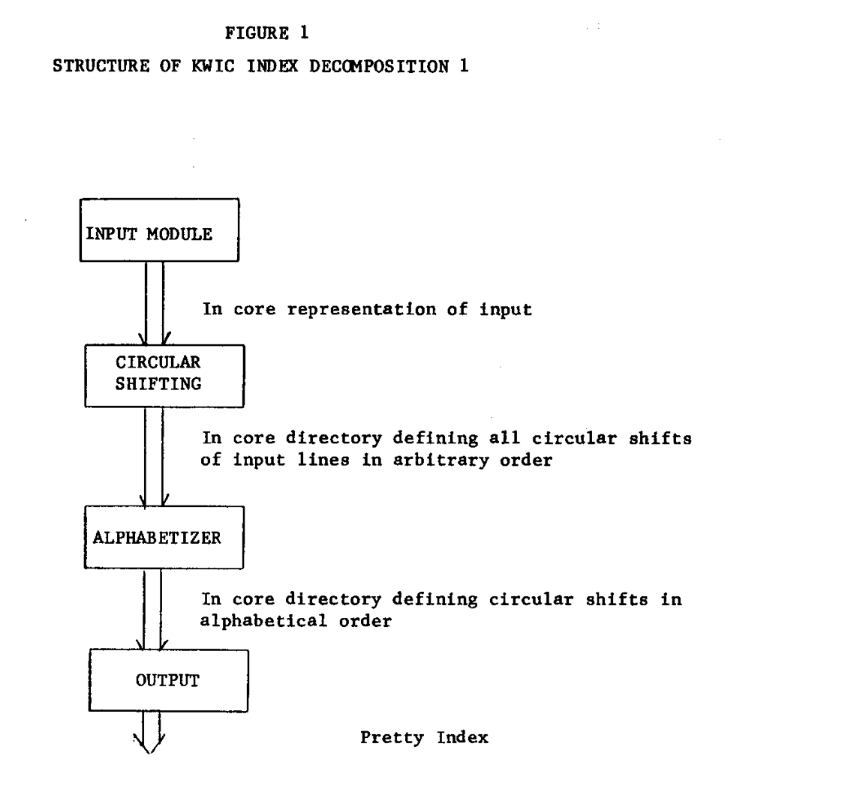
Figure 3 循环移位模块定义 在本定义中,我们假定line holder的方法有值,并且定义一个方法(TA允许我们以各种方式处理lineholder,除了把行的所有循环移位都包含在line holder中)。一个附带的功能是可以把指定行标记为"取消",尽管他们可以访问。 Function CSWROD possible values: integers initialvalues: undefined parameters: l,w,c allinteger effect: call ERCWNL(MN) if l < 1or l > p4 call ERCWNL(MN) if l > CSLINES call ERCWNW(MN) if w < 1or w > p2 call ERCWNC(MN) if c < 1or c > p3 call ERCWNC(MN) if c > CSCHARS(l,w)
Function CSWORDS possible values: integers initialvalue: 0 parameters: l an integer effect: call ERCWNL(MN) if l < 1or l > p4 call ERCWNW(MN) if l > CSLINES
Function CSLINES possible values: integers initialvalues: 0 parameters: none effect: none
Function CSCHRS possible values: integer initialvalue: 0 parameters: l,w both integers effect: call ERCCNL(MN) if l < 1or l > CSLINES call ERCCNW(MN) if w < 1or w > CSWORDS(l)
Function CSSTUP possible values: none initialvalue: not applicable parameters: none effect: call ERCNES(MN) ifSUM(1,l,'LINES','WORDS'(1)) > p4 CSLINES = SUM(1, l, 'LINES', 'WORDS'(l)) let HIP(l) = minimum k such that SUM(1, l, k, 'WORDS'(l)) .> or =. let SHI(l) = l - SUM(1, l, HIP(1) - 1, 'WORDS'(l) - 1) thenforall l such that l .< or =. CSLINES CSWORDS(l) = 'WORDS'(HIP(l)) CSCHARS(l,w) = 'CHARS'(HIP(l), (w+SHI(l))mod'CHWORDS'(l)) CSWORD(l,w,c) = 'WORD'(HIP(l), (w+SHI(l))mod'CSWORDS'(l), c)
Function ITH possible values: integers initialvalues: undefined parameters: i an integer effect: call ERAIND ifvalueoffunction undefined for parameter given
Function ALPHC possible values: integers initialvalue: ALPHC(l) = indexof l in alphabet used ALPHC(l) = infinite ifcharacternotin alphabet ALPHC(undefined) = 0 parameter: l an integer effect: call ERAABL if l notin alphabet being used, i.e., if ALPHC(1) = infinite
MappingFunction EQW possible values: true, false parameters: l1, l2, w1, w2 all integers values:EQW(l1, l2, w1, w2) = forall c('WORD'(l1, w1, c) = 'WORD'(l2, w2, c)) effect: call ERAEBL if l1 < 1or l1 > 'LINES' call ERAEBL if l2 < 1or l2 > 'LINES' call ERAEBW if w1 < 1or w1 > 'WORDS'(l1) call ERAEBW if w2 < 1or w2 > 'WORDS'(l2)
MappingFunction ALPHW possible values: true, false parameters:l1, l2, w1, w2 all integers values: ALPHW(l1, w1, l2, w2) = if !'EQW'(l1, w1, l2, w2) and k = min c such that ('WORD'(l1, w1, c) != 'WORD'(l2, w2, c)) then'ALPH'('WORD'(l1, w1, k)) < 'ALPHC'('WORD'(l2, w2, k)) elsefalse; effect: call ERAWBL if l1 < 1or l1 > 'LINES' call ERAWBL if l2 < 1or l2 > 'LINES' call ERAWBW if w1 < 1or w1 > 'WORDS'(l1) call ERAWBW if w2 < 1or w2 > 'WORDS'(l2)
MappingFunction EQL possible values: true, false parameters: l1, l2 both integers values: EQL(l1, l2) = forall k ('EQW'(l1, k, l2, k)) effect: call ERALEL if l1 < 1or l1 > 'LINES' call ERALEL if l2 < 1or l2 > 'LINES'
MappingFunction ALPHL possible values: true, false parameters: l1, l2 both integers values: ALPHL(l1, l2) = if !'EQL'(l1, l2) then (let k = min c such that 'EQW'(l1, k, l2, k)) 'ALPHW'(l1, k, l2, k) elsetrue effect: call ERAALB if l1 < 1or l1 > 'LINES' call ERAALB if l2 < 1or l2 > 'LINES'
Function ALPH possible values: none initialvalues: not applicable effect: forall i >=1and i <= 'LINES' ( ITH(i) is given values such that ( forall j >= 1and j <= LINES there exists a k such that ITH(k) = j for i > -1and i < 'LINES' (that 'ALPHL'(ITH(i), ITH(i+1))) ) )
尽管第一个例子已经展示了本文的大部分观点,再看看其他的例子也会非常有帮助。这是一个要实现Markov算法的翻译器。Markov算法在很多地方都被论述过了;作为编程语言的描述最棒的是Galler and Perlis。对于那些不熟悉的人,Markov算法可以被描述为穷人版SNOBOL。机器上唯一的内存是一个字符串(只要需要就可以随意扩展)。算法通过一系列的规则描述。每个规则包含一个待匹配的规则,和一个用于替换被匹配部分的字符串。顺序性原则标明规则的匹配遵循最左匹配原则(匹配一次则不再匹配)。当替换完成之后,第一个可应用规则仍然有效(例如,对于最后一个规则来说没有内存供匹配了,即到头了)。