在生命中的某个节点,你可能会回想起一部你和朋友都曾想看又都后悔看过的电影。或者可能你记得那些“你的团队认为找到了杀手级功能,但只是在上线之后又归于沉寂”的时刻。
好的想法在实践中可能会失败,在测试的世界中,一个普遍的好但是经常在实践中失败的主意是基于end-to-end测试周围的测试策略。
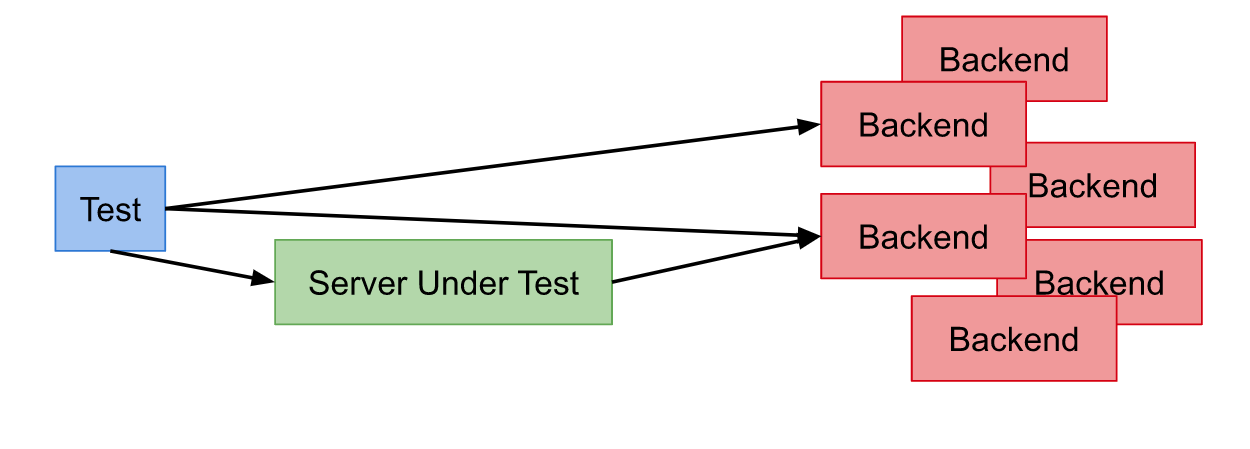
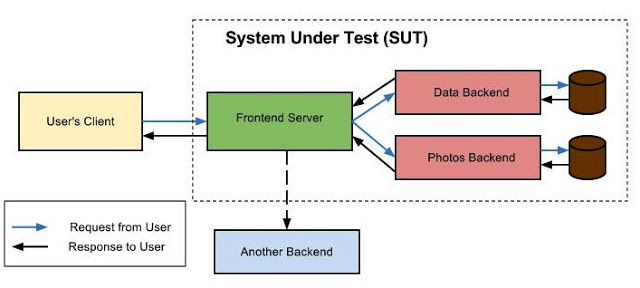
测试人员投入时间写了大量的自动化测试,包括单元测试,集成测试,和end-to-end测试,但是该策略可能大部分都投入到了用end-to-end测试来整体验证一个产品。典型情况是,这些测试模拟了真实用户场景。
理论上的End-to-End测试
虽然主要依赖于end-to-end测试是个坏点子,但却很容易说服一个理性人使其相信这个点子理论上是有意义的。
Google的十件我们已知正确的事的第一条是:”专注与用户,其他的一起以此为准”。因此,end-to-end测试专注于真实用户场景听起来是个好主意。而且,这个策略也有广泛的拥泵:
- 开发人员,喜欢它,因为这把测试工作的大部分转交给其他人负责了
- 经理人与决策者,喜欢它,因为模拟真实用户场景的测试可以帮助他们简单的判断失败的测试对于用户来说意味着什么。
- 测试人员,喜欢它,因为他们经常担心遗漏一个Bug或者时写了一个没有验证真实行为的测试用例;从用户视角写测试用例可以避免前面的问题,并且可以给测试人员一种满足感。
真实的End-to-End测试
如果这个测试策略理论上听起来这么棒,那么在实践中怎么搞锉了的呢?为了讲清楚,我在下面展示了一个组合概述,该概述基于我或是其他测试人员的真实体验。在这个概述中,一个组织正在构建一个在线文档编辑的服务(比如,Google Docs)。
让我们假设这个团队已经有一些很酷的测试基础设施可用了。每个晚上:
- 服务的最新版本都会被构建
- 这个版本会被部署到团队的测试环境
- 所有的end-to-end测试会在这个环境上执行
- 一封总结了测试结果的邮件报告会被发给整个团队
随着下一个发布日期的逐步接近,为了保证较高的产品质量标准,他们仍然要求在需求完成前要保证90%的end-to-end测试用例通过。现在,还有一天就到截止日期了:
| Days Left | Pass% | Notes |
|---|---|---|
| 1 | 5% | 所有end-to-end测试用例都挂了!登录服务挂了。所有测试用例都需要登录,因此所有测试都挂了。 |
| 0 | 4% | 我们所依赖的兄弟团队,部署到测试环境一个低质量build |
| -1 | 54% | 一名研发昨天搞挂了测试场景保存。半数左右的测试用例会在执行中保存文档。研发同学花了很长时间用于排查是否是前端bug。 |
| -2 | 54% | 确定了是个前端Bug,研发同学花了大半天的时间来排查问题的根因 |
| -3 | 54% | 昨天一个错误的修复提交合进了仓库。错误挺容易就被定为了,因此,今天一个正确的修复提交被合进了仓库 |
| -4 | 1% | 测试环境机房里发生了物理机故障 |
| -5 | 84% | 大部分小Bug都是被几个主要Bug引起的(比如登录挂了,保存场景挂了)。还有些小问题仍在处理中 |
| -6 | 87% | 应该能做到90%以上的,但是各种原因还是没做到 |
| -7 | 89.54% | 很接近90%了。昨天没有新的修复合进代码库,所以昨天一定有些测试是因为自身脆弱导致没通过的 |
分析
除了几个问题,测试还是不活了真正的bug的。
哪些是搞得比较好的
- 影响用户的Bug在被用户发现之前定位并解决了。
哪些是搞得还不够好的
- 团队完成交付,整整延迟了一个礼拜(而且还加了很多班)
- 查end-to-end测试用例失败的根因很痛苦也很消耗时间
- 其他团队的失效以及机房失效有好几天都影响了测试结果
- 许多小Bug藏在了更大的Bug后面(大坑套小坑)
- end-to-end测试有些时候还是比较脆弱的
- 开发人员必须等到第二天才能搞明白一个修复是否真的有效
所以,我们现在知道end-to-end这种测试策略的问题了,我们需要调整我们测试的方式来规避这些问题。但是怎么样才是正确的搞法呢?
测试真正的价值
通常来说,一旦发现未通过的测试用例,一个测试人员的工作就完成了。报告了一个bug,然后修复这个Bug就是开发的任务了。为了确认end-to-end测试策略到底哪里不靠谱,我们需要调出这个问题边界,从第一原则的角度来重新思考问题。如果我们“专注与用户(其他一起则随之而来)”,我们必须要问我们自己:一个失败的测试对用户的好处是什么。下面是对这个问题的回答。
一个失败的测试用例对于用户没有直接好处
尽管这句声明初看起来有些令人震惊,但这是真的。如果产品正常工作,一个测试用例能判断TA(指该产品)是否正常工作吗?如果产品出问题了,一个测试用例能判断TA(指该产品)是否出问题了吗?因此,如果一个失败的测试用例对于用户来说没什么意义,那么什么对用户来说有意义呢?
对于Bug的修复,是对用户有益的
用户只对于Bug被修复感到开心。很明显,为了修复一个Bug,你必须要知道这Bug存在与哪里。为了知道Bug藏在哪,理想中你有一个测试用例来捕获这个Bug(因为如果测试用例不能捕获Bug,那么用户就会发现这些Bug)。但是在整个流程中,从测试用例失败到Bug修复,只有在最后一步(指Bug修复)才真的产生价值。
| Stage | Failing Test | Bug Opened | Bug Fixed |
|---|---|---|---|
| Value Added | No | No | Yes |
因此,为了评估一个测试策略,不能只是评估它在发现Bug方面表现如何。也必须要评价在帮助研发修复(甚至是防范)Bug方面表现的怎么样。
简历正确的反馈回路
测试创建了一个反馈回路,可以通知开发产品是否正常工作。理想的反馈回路有多个属性:
- Fast。没有开发人员想要浪费数小时甚至数天来判断是否变更正常工作。有些时候变更不工作,没有人是完美的,并且反馈循环需要多次执行(改-测-改-测)。一个快速的反馈循环,是的修复Bug更快。如果循环足够快,开发人员就可以在讲变更检入之前就执行测试。
- Reliable。没有开发人员想要花费数小时的时间来调试一个测试用例,结果只是发现这测试用例就是比较脆弱。脆弱的测试用例减弱了开发人员对于测试的新人,并且脆弱测试用例也经常会被忽略,即使是TA们真的发现了产品问题。
- Isolates failures。为了修复Bug,开发需要找到引起Bug的具体代码位置。当一个产品包含数百万行代码时,且Bug可能在任何地方,好似大海捞针。
小处着眼,而不是大处着眼
那么,我们怎么才能创建理想的反馈回路呢?通过向更小处着眼,而不是更大。
单元测试
单元测试只测产品的一小部分,并且将该部分隔离之后测试。单元测试比较接近于理想的反馈回路:
- 单元测试 Fast。我们只需要构建一个小单元来测试,且测试用例也趋向于非常小。事实上,1/10秒的执行时间,对于单元测试来说是比较慢的。
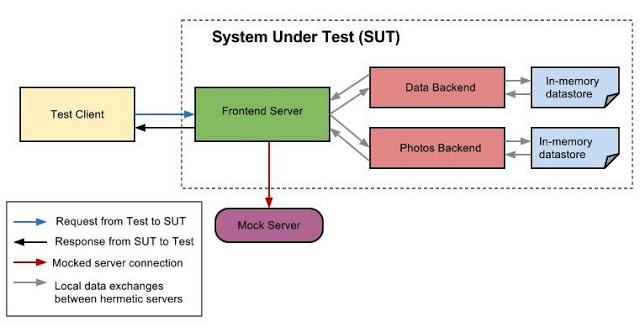
- 单元测试 Reliable。简单的系统和小单元总体上更不容易产生脆弱性。进而,单元测试的最佳实践,特别是与hermetic测试相关的实践,可以彻底移除脆弱性。
- 单元测试Isolates Failures。即使产品包含100W行代码,如果一个单元测试没通过,你也只需在单元测试覆盖的小单元中搜寻Bug。
书写高效的单元测试需要在如下领域磨炼出技巧:比如,依赖管理,mocking以及hermetic测试。在这我不会覆盖这些这些技巧,但是作为一个样例,可以参考提供给新Google员工阅读的How Google builds以及测试一个计时器。
单元测试与end-to-end测试的对比
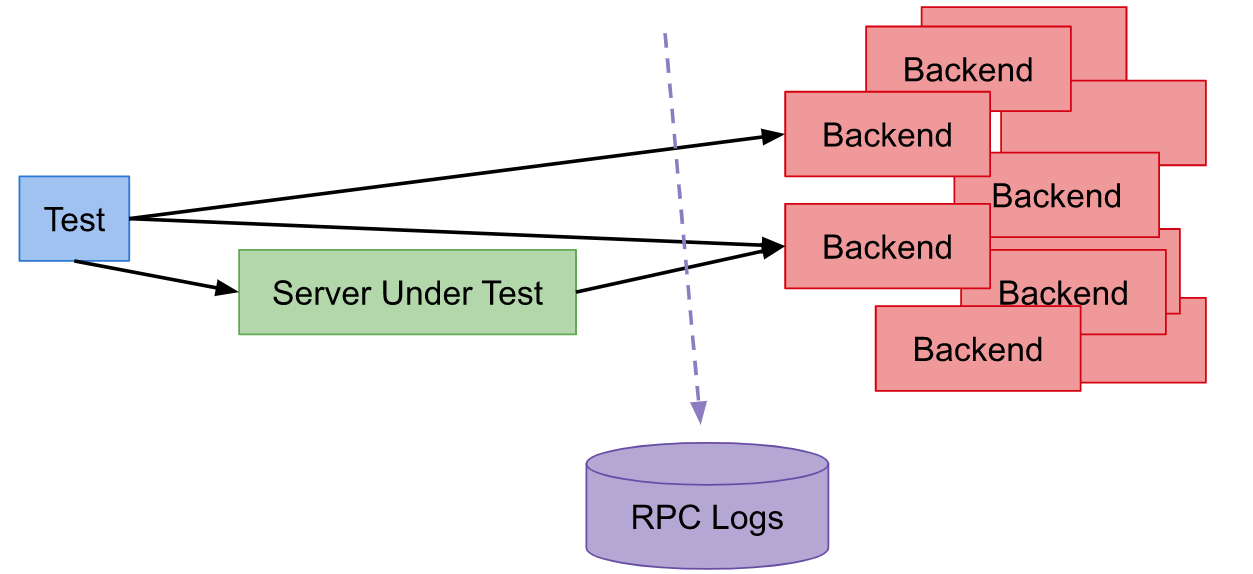
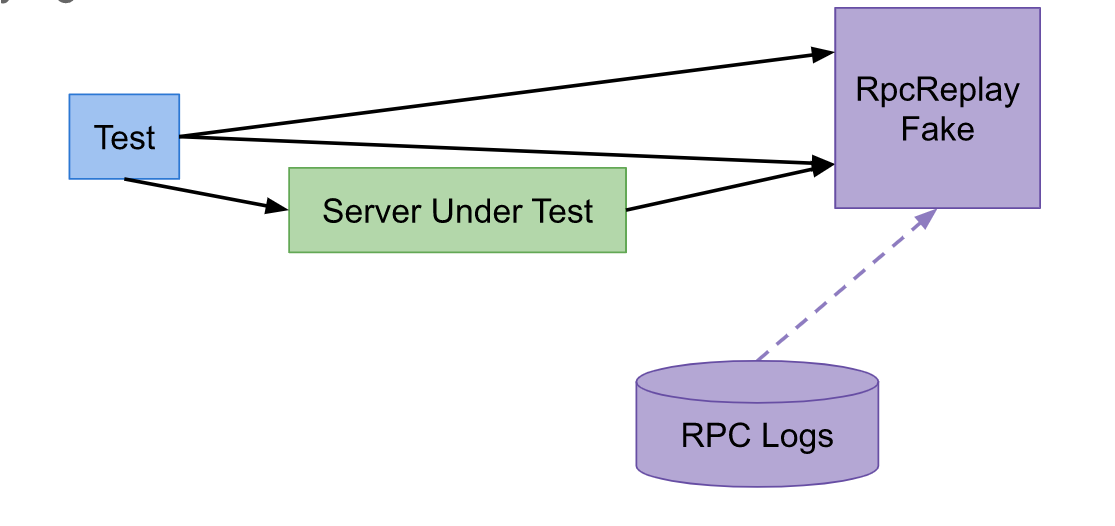
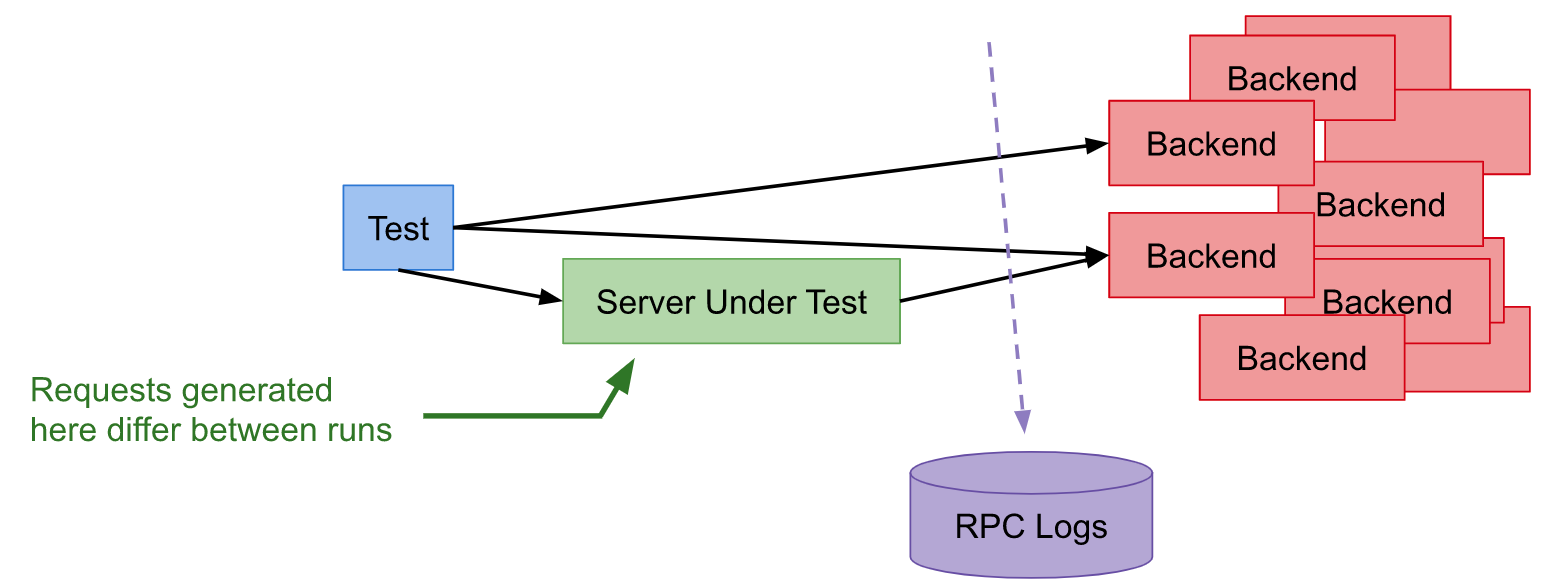
对于单元测试,你必须要等:首先等整个产品构建出来,然后等TA部署完毕,最后才能执行end-to-end测试。当测试用例执行时,脆弱性如影随形。即使一个测试用例发现了Bug,Bug也可能在产品的任何地方。
尽管end-to-end测试在模拟真实用户场景方面表现良好,但这个有点将很快被end-to-end反馈回路上的劣势冲淡。
| 1 | Unit | End-to-End |
|---|---|---|
| Fast | Yes | No |
| Reliable | Yes | No |
| Isolates Failures | Yes | No |
| 模拟真实用户 | No | Yes |
集成测试
单元测试确实有个巨大的缺点:即使每个单元都工作完好,你也不能确定他们在一起工作时是什么状态。但即使这样,你也不需要end-to-end测试。对于这种情况,可以使用一个集成测试。一个集成测试将几个单元组合起来,通常是两个单元,测试他们一起工作时的表现,以验证他们在一起工作时没问题。
如果两个单元之间的集成除了问题,且你能够写一个更小规模/更专注的集成测试来发现该问题,为什么要写一个end-to-end测试呢?如果你确实需要考虑的更广泛一点,那么你只需要“扩大一点点”来验证这些单元一起工作良好。
测试金字塔
尽管有了单元测试和集成测试之后,你还是希望有少量的end-to-end测试来验证整个系统。为了在三种测试类型中找到平衡,一图胜千言,测试金字塔表现的很到位。下面是个简化版的测试金字塔,来自于公开的Keynote:
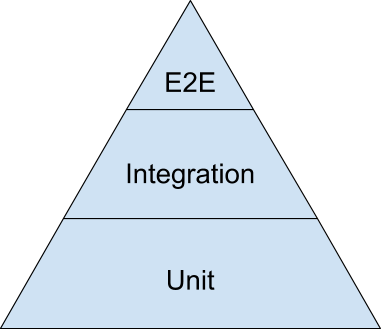
测试中最大量的内容应是金字塔底层的单元测试。当向金字塔上层移动时,测试范围变的越来越大,同时数量也应越来越少。
作为一个参考,Google通常建议70/20/10的比例分割:70%的单元测试,20%的集成测试,10%的end-to-end测试。确切的比例,每个team都会有所不同,但总体来看,应该保持金字塔的形状。要努力避免如下的反模式:
- 融化的冰激凌/倒金字塔。主要依赖于end-to-end测试,使用很少的集成测试,甚至更少的单元测试。
- 沙漏。大量的单元测试,然后用end-to-end测试来覆盖本应用集成测试覆盖的内容。沙漏底层有很多的单元测试,顶层有许多的end-to-end测试,但是中间缺少集成测试。
就像生活中的三角形更容易保持稳定一样,测试金字塔也可能是最稳定的测试策略。
文章翻译自
https://testing.googleblog.com/2015/04/just-say-no-to-more-end-to-end-tests.html