一切都从一颗小树苗开始。小树苗逐渐成长为树干,在其上又长出了许多新芽,在不知不觉间又长成了一颗茂密的参天大树.
在数字世界中也存在着这样一棵树,被称为Merkle Tree. Merkle Tree主要由根,中间节点,叶子结点组成。一棵树可以有大量的叶子结点,但叶节点不再拥有子节点。Merkle Tree用来解决什么问题呢?我们一起看看。
The Basics
一颗Merkle Tree是一个非线性,二叉,基于哈希的树状数据结构。每个叶子节点存储数据的hash值,每个中间节点存储两个子节点hash的hash.使用Merkle Tree的主要优势是数据元素(或整个数据集)的许多重要信息可被验证,而无需访问整个数据集。例如,在无需下载整个数据集的前提下,可以验证一个特定的数据元素是否是一个大数据集的一部分. 由于这些特性,Merkle Tree经常被使用在区块链等基于P2P网络构建并经常会涉及从非信任源获取数据的业态中,因此数据在获取的同时也得到了了验证. 有了Merkle Tree之后,可以避免这样的场景,即在下载完整个数据集之后,发现数据是不可验证的,因而节省了大量的时间与带宽。
区块链平台的场景下,总体来说,用户只需要同步哪些与自己账号相关的数据和事务信息。如果用户想要下载全量数据,效率则会大打折扣。因此,区块链实现了一种被称之为SPV(Simple Pay Verification)的技术。使用这项验证技术,用户可以在只需要极小量数据的前提下构建和验证Merkle Proof。这直接导致对于终端用户只需要极小的存储和带宽需求。
Merkle Tree拥有着丰富的应用场景。其中之一便是生成区块Merkle Tree,其中区块中的transaction是叶子节点。这些记录被用做这些事务确实曾发生在区块链上的证明。这篇文章主要目标是描述Ontology在实现Merkle Tree时是如何做了各种优化的。
Merkle Tree数据结构存储
大部分区块链为不同区块实现以transaction hash为叶子节点的Merkle Tree。然而在Ontology区块链的场景下,随着区块数量的增加区块Merkle Tree在不断地被动态修改,导致了一个比传统范式更复杂的场景。这自然提出了一个问题:如何存储Merkle Tree?让我们看看这个问题的不同答案。
方案一:Cache Storage
这个方案主要是缓存Merkle Tree. 但有两个明确的缺点。第一,缓存意味着树被存储在易失性内存里,当机器关机或重启时,需要重新扫描以构建完整的Merkle Tree,这是一个想对耗时的过程。同时,随着区块高度的增加,树也在不断变大。因此,内存需求在线性增加,这极大影响了扩展性。因此,我们可以很明确地说缓存不是一个长期的最优解。
方案二:KV数据库存储
这个方案主要涉及将Merkle Tree存储在KV数据库中(如LevelDB). 由于KV的简单性,将树状结构序列化/反序列化为KV的表达方式,是一个绕不开的问题。同时,获取树中一个具体节点需要多次读取操作,这无疑降低了系统的整体效率。
方案三:文件存储
由于Merkle Tree的节点都是定长的hash值,如果我们将hash值与整数形成一个1-1映射,就有可能将整棵树压缩为一个整型数组。对应的整型值先被计算出来,然后将对应节点数据存储在以该整型值为下标的数组元素中。当访问一个具体节点时,先计算出该整型数值,再直接访问该整型值为下标的数组元素。将这个数组存储在文件中可以解决Merkle Tree线性增长的问题。
有许多种将节点映射为整型的方法,最为直接的是基于树深度的逐层序列化。但,这种序列化方式有一个问题。即每次树的大小变化时,一个节点的序列号也会变化。因此,整个数据都需要被解析,序列化,再重新存储。这会极大的影响系统的运行效率。因此,文件存储方案的稳定性极大地依赖于找到一种高效的序列化方法。
Merkle Tree更新和节点序列化Schemes
除了节点序列化,使用文件存储还存在着其他问题。随着区块不断的增加,Merkle Tree的节点被不断修改,因此文件也许不断的更新和重写。这是另一个会导致效率快速降低的因素。
再增加一点难度,可能还需要一个数据一致性的处理机制。考虑这样一个假想的但一定会频繁出现的场景,节点数据被更新了,更新过程处理了一半,突然一个新的区块产生了。这会导致Merkle tree数据文件的不一致。
如果你仔细观察Merkle Tree的插入过程,Merkle Tree中存在着两种节点:临时节点,它的节点hash会随着新节点的插入而变化;稳定节点,那些不会因新节点插入而变化的节点。很容易总结出,一个节点成为稳定节点的前提是它及其子孙节点已经构成了一个完全二叉树。同时,非常明确的是临时节点的数量也是有限的(只有log(n))。临时节点数量可以由稳定节点数量退推导得出,在出入内存之后,会随着新节点的插入而变化。
因此,在Ontology的方案中,只有稳定节点被写进文件中。另一个有趣的巧合是未定节点形成的序列本身是一个稳定的序列化顺序。考虑上面提到的事实,只有一种动作会发生在文件上,那就是append。同时这解决了因重写文件可能会带来的数据一致性问题。
Merkle Tree的压缩形式
由稳定节点性质,可以推出稳定节点的字节点对于Merkle Tree的更新过程不会有任何参与度。因此,对于那些不需要提供证明服务,并且只需要计算最新的Merkle Tree根节点hash值的参与者来说,可以只简单地存储完整Merkle Tree的log(n)数量级的节点数据。这就足以表达整颗Merkle Tree的状态了,因此将需要存储的节点数量缩小到了log(n)级别,这使得可以很方便的用LevelDB的一个Key来存储这些节点。更新Merkle Tree将只需要一次读写操作。数据结构定义如下:1
2
3
4type CompactMerkleTree struct {
hashes []common.Uint256
treeSize uint32
}
计算Merkle Tree的根Hash
从压缩后的Merkle Tree的定义可以很容易发现,为了获得Merkle tree的根节点hash,存储的不稳定节点的hash array需要从后向前不断解析。算法如下:1
2
3
4
5
6
7
8
9
10
11
12func (self *CompactMerkleTree) Root() common.Uint256 {
if (len(self.hashes) == 0) {
return empty_hash();
}
hashes = self.hashes;
l := len(hashes);
accum = hashes[l-1]; //从最后一个节点(会参与root hash计算的)开始
for i:=l - 2; i >= 0; i-- { //从后向前,即使需要计算root hash的顺序,后面的图示中将明确阐释
accum = hash_children(hashes[i], accum); //计算子节点hash的hash
}
return accum;
}
这里的empty_hash返回空hashes, hash_children方法将两个子节点hash计算成为父节点hash.
插入新的叶子节点
当新的叶子节点插入时,动态更新依据当前Merkle Tree的状态被执行。具体的算法如下:1
2
3
4
5
6
7
8
9
10func (self *CompactMerkleTree) Appen(leaf common.Uint256) {
size := len(self.hashes);
for s := self.treeSize; s%2 == 1; s = s >> 1 { //终止条件是再向前都是完全二叉树了(只有有单数才是非完全);s>>1,每次向上移动一层;
leaf = hash_children(selft.hashes[s - 1], leaf); //根据新叶子和上一层的左侧兄弟节点计算hash.
size -= 1;
}
self.treeSize += 1;
self.hashes = self.hashes[0:szie];
self.hashes = append(self.hashes, leaf);
}
#随着Merkle Tree不断增长,数据变化的示意图
在hash values以及存储文件中压缩存储的数据随Merkle Tree增长而变化的情况展示如下:
第一张图是Merkle Tree只有单一节点的情况

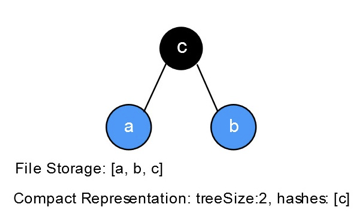
当一个新节点b插入Merkle Tree时,size会+1. 新节点b可以用来与a一起计算出hash值c.
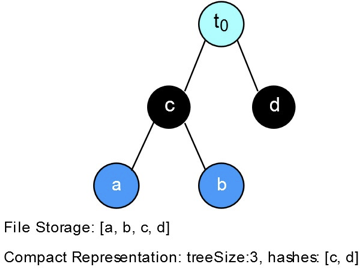
当一个新节点d插入时,由于当前树是完全二叉树, 该节点独立成为一个新子树. 树的size加1
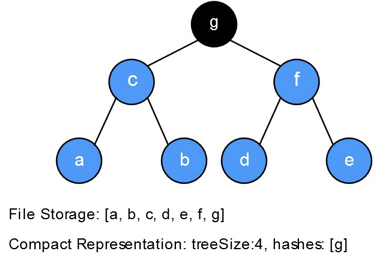
此时,每次有一个新节点插入时,我们都可以通过之前讨论过的算法得到对应的位置和hash值。
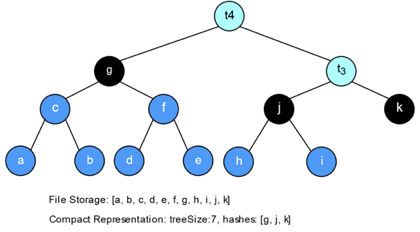
总结
Merkle Tree在不同的场景中存在着广泛的应用。在Ontology的场景下,Merkle Tree的一个应用是以叶节点的形式记录每个区块,然后为transactions是否在链上发生过以及是否是这些区块的一部分提供证明。
对于那些不需要提供证明的场景, Merkle Tree可以显著的提升共识节点的性能和存储效率。Ontoloty在实现Merkle Tree时只记录了关键节点。其效果是,我们可以仅通过一次LevelDB读写更新Merkle Tree。时间复杂度被减小到O(logn).
更进一步,当需要提供证明服务时,本文提到的方案可以解决存储文件需要频繁重写的问题,并通过使文件操作只有append一种来简化一致性负担。
文章翻译子
https://medium.com/ontologynetwork/everything-you-need-to-know-about-merkle-trees-82b47da0634a